一次漏洞扫描的爬虫
最近在写漏洞扫描的报告,要从漏扫工具导出的报告中重新编写一份成公司的报告,但是里面东西太多啦~,让我一个一个复制粘贴整理?No!会python的人绝不手动搞~
爬取数据
用python爬取网站的数据,一般的话就是 requests + bs4,但是问题就来了,本地的文件并不能有requests进行请求,而且bs4生成我们的soup对象的时候,只需要我们的html代码,所以我就直接以文件的形式打开了。1
2htmlf = open('C:/Users/Administrator/Desktop/export/Document.html','r')
content = htmlf.read()
这样我们的html代码就复制给content。
然后在写 soup 抓取数据的时候发现抓取不到、编码问题,尝试了半天不行,就去一个python的群里面去请教了一番。。


最后大佬们让我不用bs4了,去用xpath,,就去尝试了一下,哦豁,居然还成了~ 开心

思路和bs4都是一样的,先生成一个对象,然后利用对象的方法去获取标签里面的内容,这里直接贴上代码和结果: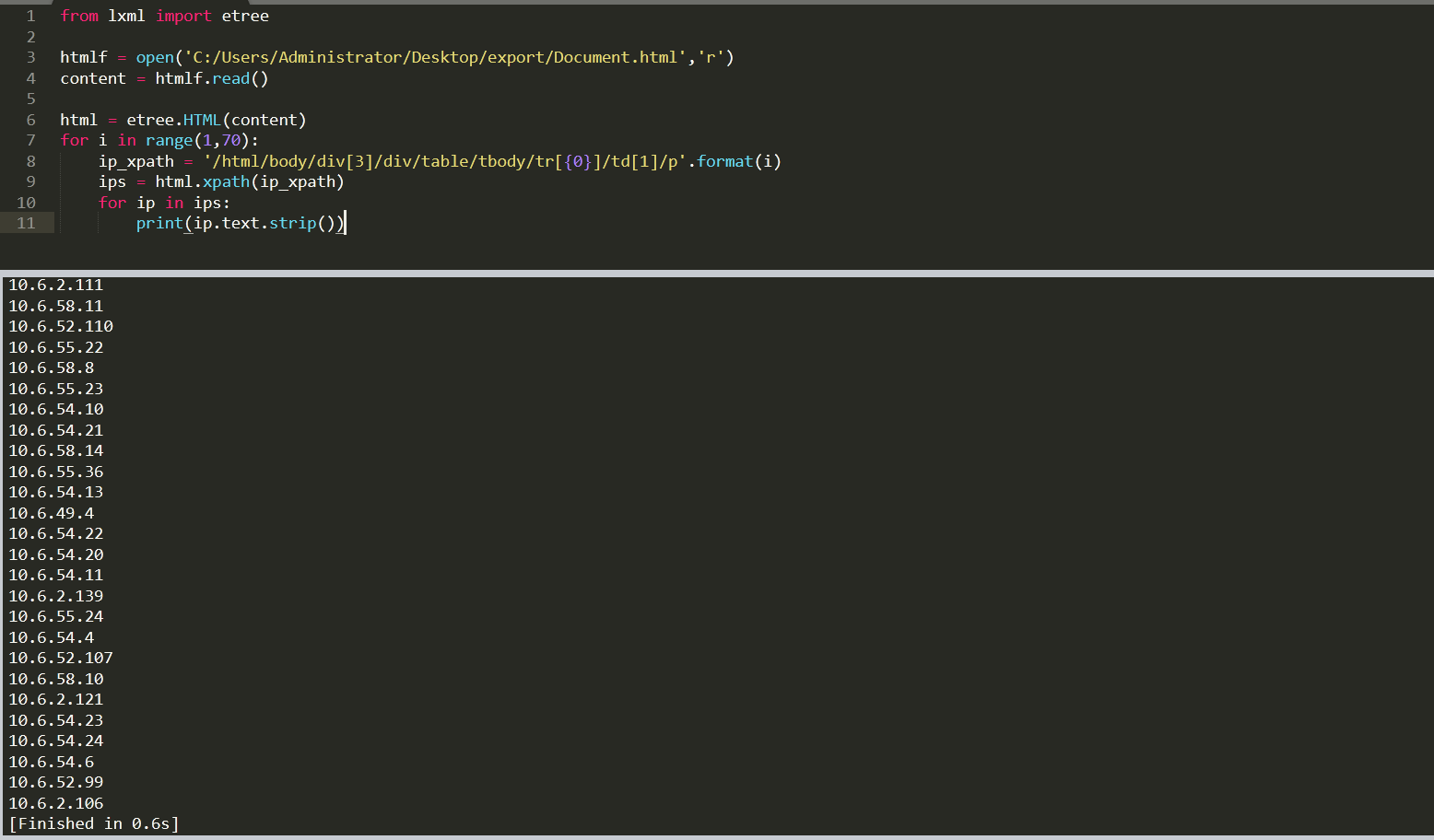
这里是源文档里面的内容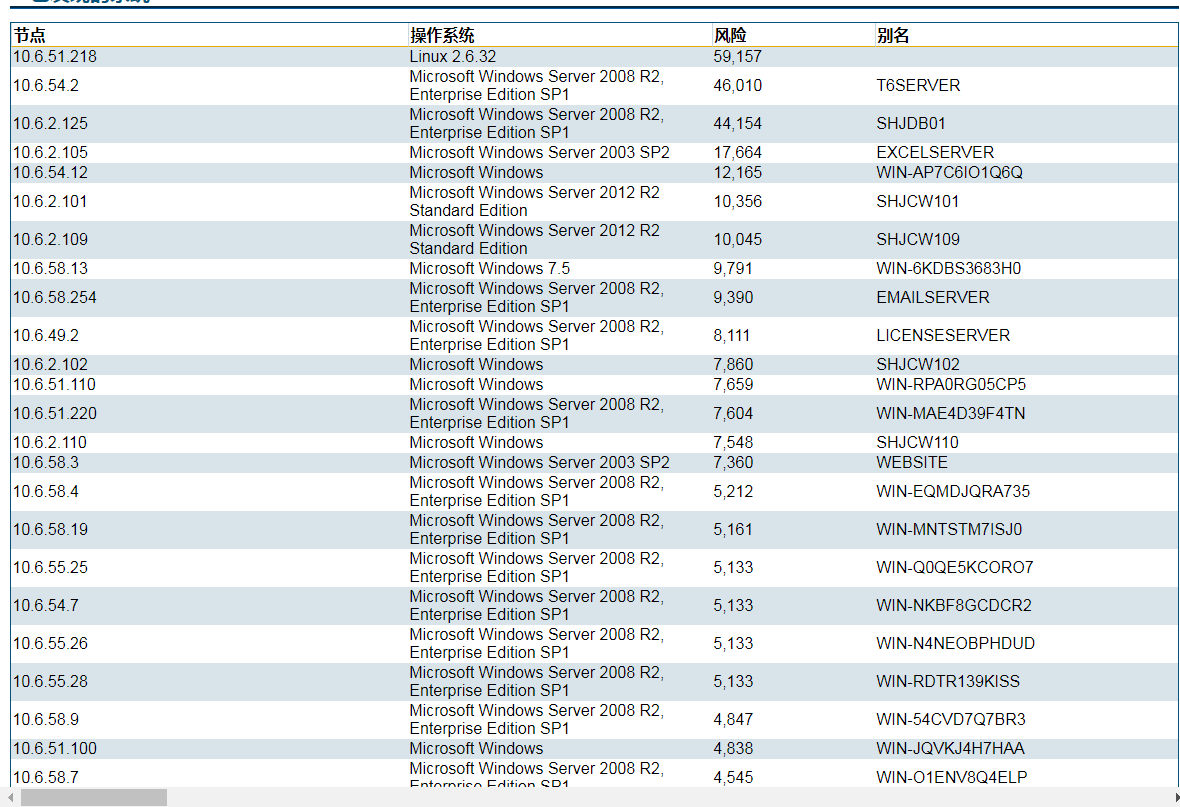
既然可以抓取,这里我的几个需求是这样的:
文档一:统计每一个ip中高危漏洞、中危漏洞、低危漏洞的数量。
文档二:爬取每一个漏洞对应的名称、详情、解决方法、参考、CVE编号、CVSS评分涉及IP。
文档一:统计漏洞数量
这里的思路很简单,获取每一个ip中扫描出的漏洞对应的等级,一个for循环,然后i++;
每一个ip的xpath:1
/html/body/div[5]/h2[n]/a/text()
获取ip:1
2
3
4
5
6
7
8
9
10
11
12#coding=utf-8
from lxml import etree
htmlf = open('C:/Users/Administrator/Desktop/Document.html','r')
content = htmlf.read()
html = etree.HTML(content)
# print(html)
for i in range(1,70):
ip_xpath = "/html/body/div[5]/h2[{0}]/a/text()".format(i)
ip = html.xpath(ip_xpath)
print(ip[0])
每一个ip下漏洞等级对应的xpath:1
2/html/body/div[5]/div[1]/div[2]/table/tbody/tr[2]/td[3]/p
/html/body/div[5]/div[1]/div[2]/table/tbody/tr[3]/td[3]/p
获取每一个ip下的漏洞等级:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31#coding=utf-8
from lxml import etree
htmlf = open('C:/Users/Administrator/Desktop/Document.html','r')
content = htmlf.read()
html = etree.HTML(content)
# print(html)
high = 0
mid = 0
low = 0
for i in range(2,1000):
level_xpath = "/html/body/div[5]/div[2]/div[2]/table/tbody/tr[{0}]/td[3]/p/text()".format(i)
try:
level = html.xpath(level_xpath)
if str(level[0].encode('unicode-escape')) == '\u9ad8':
# print('high')
high +=1
elif str(level[0].encode('unicode-escape')) == '\u4e2d\u7b49':
# print("mid")
mid +=1
elif str(level[0].encode('unicode-escape')) == '\u4f4e':
# print('low')
low +=1
except:
pass
print(high)
print(mid)
print(low)
然后整合在一起:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40#coding=utf-8
from lxml import etree
htmlf = open('C:/Users/Administrator/Desktop/Document.html','r')
content = htmlf.read()
html = etree.HTML(content)
# print(html)
ip_list = []
for i in range(1,70):
ip_xpath = "/html/body/div[5]/h2[{0}]/a/text()".format(i)
ip = html.xpath(ip_xpath)
# print(ip[0])
ip_list.append(ip[0])
# print(ip_list)
for i in range(1,70):
high = 0
mid = 0
low = 0
ip = ip_list[i-1]
for m in range(2,200):
level_xpath = "/html/body/div[5]/div[{0}]/div[2]/table/tbody/tr[{1}]/td[3]/p/text()".format(i,m)
# print(level_xpath)
try:
level = html.xpath(level_xpath)
if str(level[0].encode('unicode-escape')) == '\u9ad8':
# print('high')
high +=1
elif str(level[0].encode('unicode-escape')) == '\u4e2d\u7b49':
# print("mid")
mid +=1
elif str(level[0].encode('unicode-escape')) == '\u4f4e':
# print('low')
low +=1
except:
pass
print('[+]IP: {3} FOUND [HIGH] {0} [MID] {1} [LOW] {2}').format(high,mid,low,ip)
原谅我的代码写的垃圾 ==
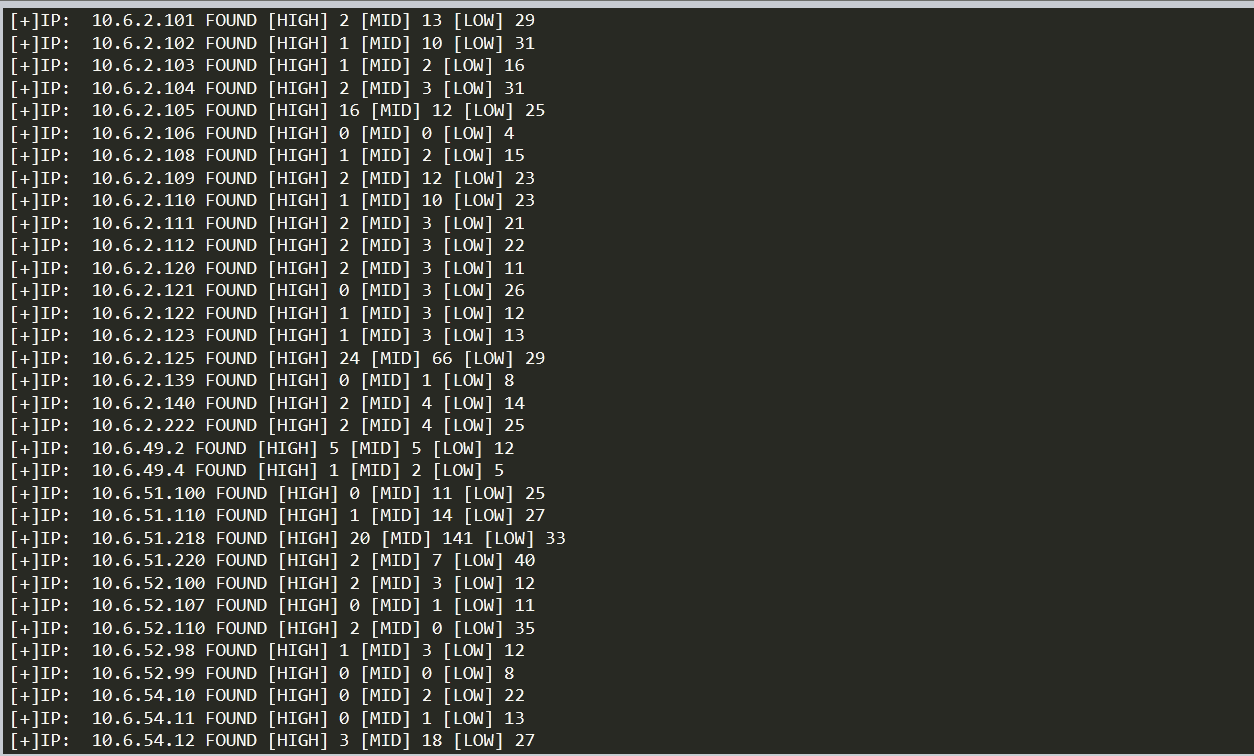
文档二:爬取漏洞相关信息
漏洞分为 关键漏洞、严重漏洞和中等漏洞。
没啥说的,直接干:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66#coding=utf-8
#关键漏洞信息脚本,其他两个更换div的节点就行了。
#严重漏洞xpath:
from lxml import etree
htmlf = open('C:/Users/Administrator/Desktop/export/Document.html','r')
content = htmlf.read()
html = etree.HTML(content)
for i in range(1,78):
print('======================================================================')
Refer_info = ''
try:
#爬取标题和信息
title_xpath = '/html/body/div[4]/div[1]/h3[{0}]/a/text()'.format(i)
title = html.xpath(title_xpath)
detail_xpath = '/html/body/div[4]/div[1]/div[{0}]/div[1]/p/text()'.format(i)
detail = html.xpath(detail_xpath)
print("[+]title IN VUL[{0}]".format(i) + '\r' + title[1].strip())
if detail[0].strip() != "":
print('[+]DETAIL IN VUL[{0}]'.format(i) + '\r'+ detail[0].strip())
else:
print('[+]DETAIL IN VUL[{0}]'.format(i) + '\r'+ detail[1].strip())
#爬取解决办法
solution_xpath = '/html/body/div[4]/div[1]/div[{0}]/div[4]/p[3]//text()'.format(i)
solution = html.xpath(solution_xpath)
solution_info = ""
for M in range(len(solution)):
solution_info = solution_info + solution[M].strip()
if solution_info.strip() == "":
solution_xpath = '/html/body/div[4]/div[1]/div[{0}]/div[4]/p[2]//text()'.format(i)
solution = html.xpath(solution_xpath)
solution_info = ""
for M in range(len(solution)):
solution_info = solution_info + solution[M].strip()
if solution_info.strip() == "":
solution_xpath = "/html/body/div[4]/div[1]/div[{0}]/div[4]/div/ul//text()".format(i)
solution = html.xpath(solution_xpath)
# print(solution)
solution_info = ""
for M in range(len(solution)):
solution_info = solution_info + solution[M].strip()
print('[+]SOLUTION IN VUL[{0}]'.format(i) + '\r'+solution_info)
#爬取参考
for j in range(2,100):
try:
refer_xpath = '/html/body/div[4]/div[1]/div[{0}]/div[3]/div/table/tbody/tr[{1}]//text()'.format(i,j)
refer = html.xpath(refer_xpath)
refer_info = refer[2].strip() + ":" + refer[6].strip() + refer[8].strip()
Refer_info = Refer_info + refer_info + '\r'
except:
pass
print('[+]REFER IN VUL[{0}]'.format(i) + '\r'+Refer_info)
except:
pass
#爬取节点
print('[+]NODE IN VUL[{0}]'.format(i))
for j in range(2,100):
try:
node_xpath = '/html/body/div[4]/div[1]/div[{0}]/div[2]/div/table/tbody/tr[{1}]/td[1]/p/text()'.format(i,j)
node = html.xpath(node_xpath)
print(node[0].strip())
except:
pass
严重 漏洞
中等 漏洞
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 sher10cksec@foxmail.com
文章标题:一次漏洞扫描的爬虫
本文作者:sher10ck
发布时间:2019-08-10, 16:23:36
最后更新:2020-01-13, 12:51:09
原始链接:http://sherlocz.github.io/2019/08/10/一次漏洞扫描的爬虫/版权声明: "署名-非商用-相同方式共享 4.0" 转载请保留原文链接及作者。