58爬虫租房信息
工作时都会有租房的需求,如何找到房源好,中介收费低,离公司方便环境又好的房子,点开租房软件一个一个点开看的头大,就想着自己写个脚本也好方便以后租房之需吧。
整个大体的思路是这个样子的:
- 爬取58上租房的信息(标题、价格、地址等)
- 整理这些信息,并按照个人喜好挑选出一部分自己会考虑的房间
- 根据地图API获取房间离公司的距离,乘车方式等
爬取58上的房源信息
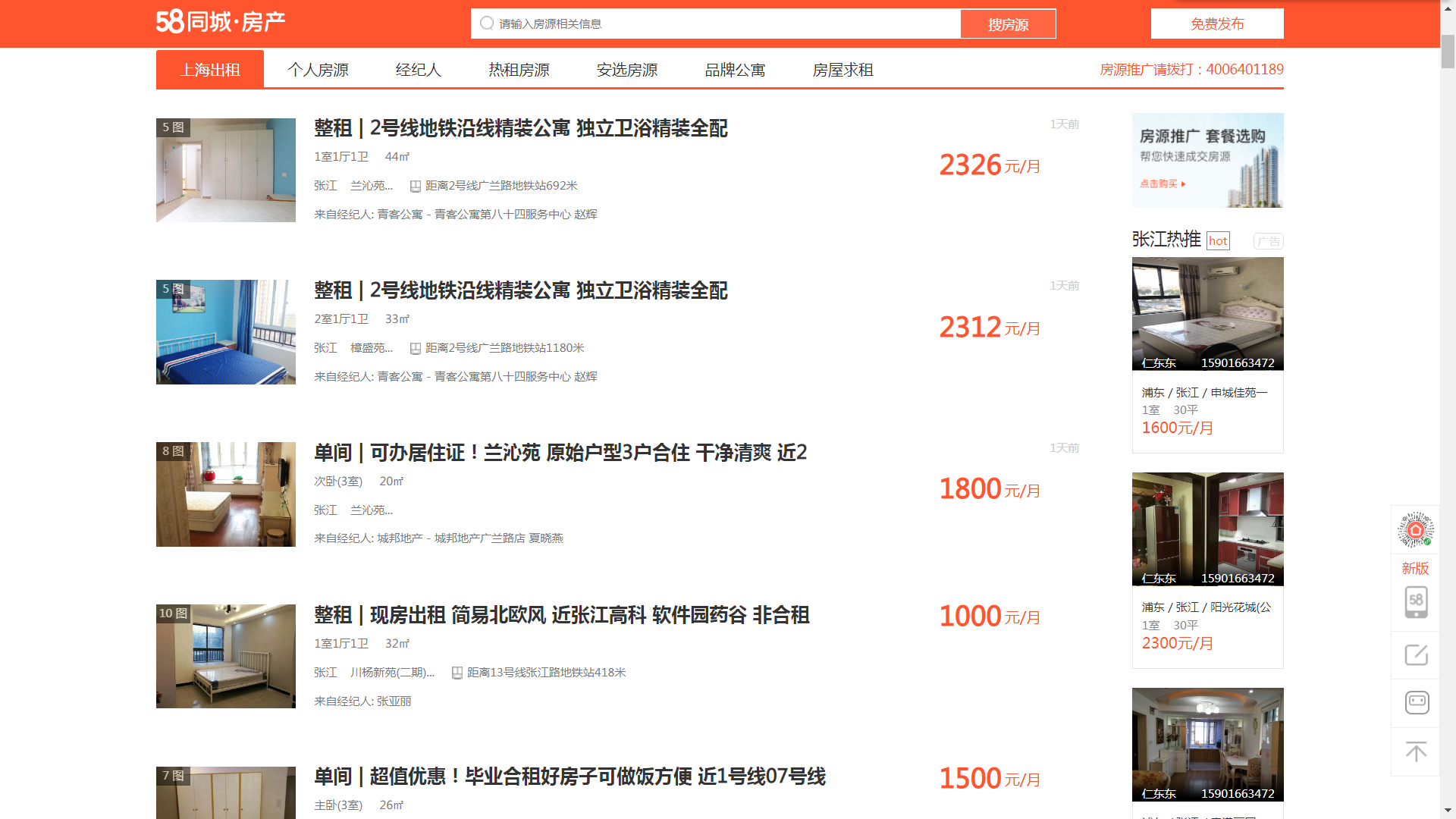
爬取每个房屋信息单独的url
这里假设我们要租上海浦东区张江的房子,里面的合租整租我们占时不考虑,可以根据个人的需求来修改第一步的url。
首先我们发送请求:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19#发送请求给服务器,返回完整的html代码
#coding=utf-8
import requests
from bs4 import BeautifulSoup
url = "https://sh.58.com/zhangjiang/chuzu/?PGTID=0d3090a7-0058-33e4-c0a2-7d7c3ae004ea&ClickID=2"
headers = {
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'referer':'https://sh.58.com/pudongxinqu/chuzu/?PGTID=0d3090a7-0000-228d-fd57-d8705ee0c998&ClickID=2',
'Accept-Language': 'zh-CN,zh;q=0.9',
'cookie':'f=n; id58=e87rZl0TJa2z39QCAxUBAg==; commontopbar_new_city_info=2%7C%E4%B8%8A%E6%B5%B7%7Csh; city=sh; 58home=sh; commontopbar_ipcity=sh%7C%E4%B8%8A%E6%B5%B7%7C0; 58tj_uuid=71c22291-d16b-4a98-9f52-b966bb7b6a4d; new_uv=1; utm_source=; spm=; init_refer=; als=0; xxzl_deviceid=WOSLGElaJtCrMADMgesxgamePUacSk1MetcNqhv%2FtLyHIE5fxIPiaasphNysWfb0; new_session=0'
}
r = requests.get(url,headers=headers)
doc = r.content
别问我header怎么设置了这么多,发现要是只有cookie或者ua就会ban的很快
从返回的html代码中获取我们想要的信息,我们这里首先获取每个标题里面的url值:1
2
3
4
5
6#通过BeautifulSoup获取每个a标签中单个url
doc = r.content
soup = BeautifulSoup(doc,'lxml')
info = soup.select("body > div.list-wrap > div.list-box > ul > li:nth-of-type(1) > div.des > h2 > a")
href = info[0].get("href")
#title = info[0].get_text().strip()
我们拿到url,是因为很多细节的信息都需要打开这个新的网页才能看得见,比方说楼层、朝向、押付比例等,更细节的包括小区物业费用、出租人信息等等。
每一页141个房间可供我们选择,每个房间的selector不同的值就在nth-of-type括号中的值,所以我们可以循环遍历出来,我们这样写:1
2
3
4
5
6
7
8
9#获取每个a标签中的链接
soup = BeautifulSoup(doc,'lxml')
for num in range(1,5):
selector = "body > div.list-wrap > div.list-box > ul > li:nth-of-type(" + str(num) +") > div.des > h2 > a"
info = soup.select(selector)
title = info[0].get_text().strip()
href = info[0].get("href")
print(href)
我们拿几个出来测试,得到的结果如下:1
2
3
4https://jxjump.58.com/service?target=FCADV8oV3os7xtAj_6pMK7rUlr0r0n6X--JC-4IqY1hBWqbTZpk1zEffDjvZrKof8T9H1Etf3gzeNV-iaypDs3m8pp1VhHeHCQZVXx_7k2_EqtKqz8pIhKDqZH122xqWC8ZcypM3b6VbDKBeP_9hhvDSfssl3oc6s5mPfZtAUEnEhkw7Zw_O3I9nVVHdFoqNyNhGQb0dhhWQbZQq5pNQQ41pw_6ApDR5hWRpH8YZE29olTwTE4ckMMZVf0w&pubid=79473471&apptype=0&shangquan=zhangjiang&psid=108667768204675942046138126&entinfo=38598836663554_0&cookie=|||e87rZl0TJa2z39QCAxUBAg==&fzbref=0&key=¶ms=rankbusitime0099^desc
https://jxjump.58.com/service?target=FCADV8oV3os7xtAj_6pMK7rUlr0r0n6X--JC-4IqY1hBWqbTZpk1zEffDjpdRkNz3Q5xoKYl4Bi0ja0Qz1KjGFmpxFK-x4-JSZ5F0yBP1ZKMCGY2mDgRot50g19_ZUbS4WGa7eEvZYetOdm4mDTvOU7qKuYukfCbRGVaWhwAwIAsnVFXu-HMWW1OcAosiu1SCX0XjaRATdcmvhizlGOiu9cSVpUgnTnuV4ut2oMzJts5psgVkxIx79qB4kA&pubid=79472253&apptype=0&shangquan=zhangjiang&psid=108667768204675942046138126&entinfo=38598797535635_0&cookie=|||e87rZl0TJa2z39QCAxUBAg==&fzbref=0&key=¶ms=rankbusitime0099^desc
https://jxjump.58.com/service?target=FCADV8oV3os7xtAj_6pMK7rUlr0r0n6X--JC-4IqY1hBWqbTZpk1zEffDjpdRkNz3Q5xoKYl4Bi0ja0RW27rsdrjEZjzCCNYt501oyBP1ZKMCGY2mDgRot50g19_ZUbS4WGa7eEvZYetOdm4mDTvOU7qKuYukfCbRGVaWhwAwIAsnVFXu-HMWW1OcAosiu1SCX0XjaRATdcmvhiywDSDDfRRtSEgnTnuV4ut2oMzJts5psgVkxIx79qB4kA&pubid=79472281&apptype=0&shangquan=zhangjiang&psid=108667768204675942046138126&entinfo=38598798403606_0&cookie=|||e87rZl0TJa2z39QCAxUBAg==&fzbref=0&key=¶ms=rankbusitime0099^desc
https://jxjump.58.com/service?target=FCADV8oV3os7xtAj_6pMK7rUlr0r0n6X--JC-4IqY1hBWqbTZpk1zEffDjvZrKof8T9H1Etf3gzeNV-jDns1YOnUtP3RXBI_UIg4Zx_7k2_EqtKqz8pIhKDqZH122xqWC8ZcypM3b6VbDKBeP_9hhvDSfssl3oc6s5mPfZtAUEnEhkw7Zw_O3I9nVVHdFoqNyNhGQVtu67Ha4xGbOAURgPq7SpaApDR5hWRpH8YZE29olTwTE4ckMMZVf0w&pubid=79472321&apptype=0&shangquan=zhangjiang&psid=108667768204675942046138126&entinfo=38598798856093_0&cookie=|||e87rZl0TJa2z39QCAxUBAg==&fzbref=0&key=¶ms=rankbusitime0099^desc
然后拿出一个打开,感觉很明显就是一个跳转连接,抓包看下返回包中的内容:
真实的url就在返回包中了,但是后来我发现就这个跳转的url自动会跳转到真实的url当中去,并且有些url就直接是真实的url,于是获取真实url这一步我就省略掉了.
实现翻页功能爬取信息
那么一页的url链接我们都能处理好了,接下来就想想后面每翻一页怎么写啊。
对比一下就可以很明显的发现,每一页url的区别:
1 | 第一页: |
同理,我们只需要更改pn后面的数字就能跳转到相应的页数了,我们写一个函数来得到每一页的url:1
2
3def get_page_url(page):
url = 'https://sh.58.com/zhangjiang/chuzu/pn' + str(num) + '/?PGTID=0d3090a7-0184-ff58-4c2f-bcb6308f148a&ClickID=2'
return url
上面的代码梳理下,我们每页提取5个url,最终运行的效果如下。
爬取每一个房屋的相关信息
接下来我们就根据一个页面,挑选出其中有价值的信息。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35#coding=utf-8
import requests
from bs4 import BeautifulSoup
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
url = 'https://sh.58.com/hezu/38598820663309x.shtml?entinfo=38598820663309_0&shangquan=zhangjiang&fzbref=1¶ms=rankbusitime0099^desc&psid=102811199204675916490173388&iuType=gz_2&ClickID=2&cookie=|||e87rZl0TJa2z39QCAxUBAg==&PGTID=0d3090a7-0184-f0a7-c26c-2bcbe0c8eb7c&apptype=0&key=&pubid=79472994&trackkey=38598820663309_e13ddfe9-65a2-4080-9b96-9ea2ae0ba79c_20190626225916_1561561156741&fcinfotype=gz'
headers = {
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'referer':'https://sh.58.com/pudongxinqu/chuzu/?PGTID=0d3090a7-0000-228d-fd57-d8705ee0c998&ClickID=2',
'Accept-Language': 'zh-CN,zh;q=0.9',
'cookie':'xxxxxxxxxxx'
}
r = requests.get(url,headers=headers)
soup = BeautifulSoup(r.content,'lxml')
#押金
deposit = soup.select("body > div.main-wrap > div.house-basic-info > div.house-basic-right.fr > div.house-basic-desc > div.house-desc-item.fl.c_333 > div > span.c_ff552e > b")
print('[+]押金:' + deposit[0].get_text())
#押付比例
payment = soup.select("body > div.main-wrap > div.house-basic-info > div.house-basic-right.fr > div.house-basic-desc > div.house-desc-item.fl.c_333 > div > span.c_333")
print('[+]押付比例:' + payment[0].get_text())
#租赁方式
mode = soup.select("body > div.main-wrap > div.house-basic-info > div.house-basic-right.fr > div.house-basic-desc > div.house-desc-item.fl.c_333 > ul > li:nth-of-type(1) > span:nth-of-type(2)")
print('[+]租赁方式:' + mode[0].get_text())
#房屋类型
form = soup.select("body > div.main-wrap > div.house-basic-info > div.house-basic-right.fr > div.house-basic-desc > div.house-desc-item.fl.c_333 > ul > li:nth-of-type(2) > span.strongbox")
print('[+]房屋类型:' + form[0].get_text())
#朝向楼层
floor = soup.select("body > div.main-wrap > div.house-basic-info > div.house-basic-right.fr > div.house-basic-desc > div.house-desc-item.fl.c_333 > ul > li:nth-of-type(3) > span.strongbox")
print('[+]朝向楼层:' + floor[0].get_text())
#所在小区
estate = soup.select("body > div.main-wrap > div.house-basic-info > div.house-basic-right.fr > div.house-basic-desc > div.house-desc-item.fl.c_333 > ul > li:nth-of-type(4) > span:nth-of-type(2) > a")
print('[+]所在小区:' + estate[0].get_text())
我们运行一下,看下效果:1
2
3
4
5
6
7[+]押金:龒龒閏龤
[+]押付比例:押一付一
[+]租赁方式:合租 - 主卧 - 男女不限
[+]房屋类型:龒室龒厅龒卫 龒餼 平 精装修
[+]朝向楼层:南 低层 / 餼龒层
[+]所在小区:贝越流明新苑
[Finished in 1.4s]
哦豁,凉凉,数字乱码了哦亲~
刚开始以为是编码的问题,然后转换成unicode之后发现unicode不对,并不是每个数字对应的unicode,我们来看看源码是怎么说的: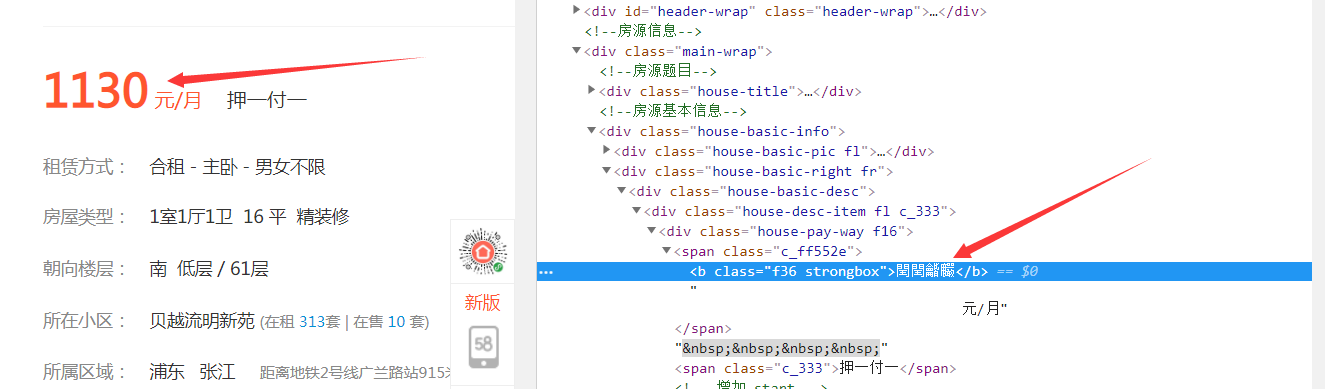
这个是打开网页呈现的乱码,我们将网页保存到本地,然后查看源码:
这里的数值变成了:1
餼餼麣龒
这让我想起了之前也遇到过这种情况,应该是网站在加载的同时给字体转换了。
然后找找网页加载时加载的东西,能不能有新的发现?

这里加载了一种字体,请求的数据如下:1
data:application/font-ttf;charset=utf-8;base64,AAEAAAALAIAAAwAwR1NVQiCLJXoAAAE4AAAAVE9TLzL4XQjtAAABjAAAAFZjbWFwq8V/YgAAAhAAAAIuZ2x5ZuWIN0cAAARYAAADdGhlYWQV+vdBAAAA4AAAADZoaGVhCtADIwAAALwAAAAkaG10eC7qAAAAAAHkAAAALGxvY2ED7gSyAAAEQAAAABhtYXhwARgANgAAARgAAAAgbmFtZTd6VP8AAAfMAAACanBvc3QFRAYqAAAKOAAAAEUAAQAABmb+ZgAABLEAAAAABGgAAQAAAAAAAAAAAAAAAAAAAAsAAQAAAAEAAOblqw5fDzz1AAsIAAAAAADZOdYYAAAAANk51hgAAP/mBGgGLgAAAAgAAgAAAAAAAAABAAAACwAqAAMAAAAAAAIAAAAKAAoAAAD/AAAAAAAAAAEAAAAKADAAPgACREZMVAAObGF0bgAaAAQAAAAAAAAAAQAAAAQAAAAAAAAAAQAAAAFsaWdhAAgAAAABAAAAAQAEAAQAAAABAAgAAQAGAAAAAQAAAAEERAGQAAUAAAUTBZkAAAEeBRMFmQAAA9cAZAIQAAACAAUDAAAAAAAAAAAAAAAAAAAAAAAAAAAAAFBmRWQAQJR2n6UGZv5mALgGZgGaAAAAAQAAAAAAAAAAAAAEsQAABLEAAASxAAAEsQAABLEAAASxAAAEsQAABLEAAASxAAAEsQAAAAAABQAAAAMAAAAsAAAABAAAAaYAAQAAAAAAoAADAAEAAAAsAAMACgAAAaYABAB0AAAAFAAQAAMABJR2lY+ZPJpLnjqeo59kn5Kfpf//AACUdpWPmTyaS546nqOfZJ+Sn6T//wAAAAAAAAAAAAAAAAAAAAAAAAABABQAFAAUABQAFAAUABQAFAAUAAAABgAFAAkABAAKAAMABwACAAEACAAAAQYAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAADAAAAAAAiAAAAAAAAAAKAACUdgAAlHYAAAAGAACVjwAAlY8AAAAFAACZPAAAmTwAAAAJAACaSwAAmksAAAAEAACeOgAAnjoAAAAKAACeowAAnqMAAAADAACfZAAAn2QAAAAHAACfkgAAn5IAAAACAACfpAAAn6QAAAABAACfpQAAn6UAAAAIAAAAAAAAACgAPgBmAJoAvgDoASQBOAF+AboAAgAA/+YEWQYnAAoAEgAAExAAISAREAAjIgATECEgERAhIFsBEAECAez+6/rs/v3IATkBNP7S/sEC6AGaAaX85v54/mEBigGB/ZcCcwKJAAABAAAAAAQ1Bi4ACQAAKQE1IREFNSURIQQ1/IgBW/6cAicBWqkEmGe0oPp7AAEAAAAABCYGJwAXAAApATUBPgE1NCYjIgc1NjMyFhUUAgcBFSEEGPxSAcK6fpSMz7y389Hym9j+nwLGqgHButl0hI2wx43iv5D+69b+pwQAAQAA/+YEGQYnACEAABMWMzI2NRAhIzUzIBE0ISIHNTYzMhYVEAUVHgEVFAAjIiePn8igu/5bgXsBdf7jo5CYy8bw/sqow/7T+tyHAQN7nYQBJqIBFP9uuVjPpf7QVwQSyZbR/wBSAAACAAAAAARoBg0ACgASAAABIxEjESE1ATMRMyERNDcjBgcBBGjGvv0uAq3jxv58BAQOLf4zAZL+bgGSfwP8/CACiUVaJlH9TwABAAD/5gQhBg0AGAAANxYzMjYQJiMiBxEhFSERNjMyBBUUACEiJ7GcqaDEx71bmgL6/bxXLPUBEv7a/v3Zbu5mswEppA4DE63+SgX42uH+6kAAAAACAAD/5gRbBicAFgAiAAABJiMiAgMzNjMyEhUUACMiABEQACEyFwEUFjMyNjU0JiMiBgP6eYTJ9AIFbvHJ8P7r1+z+8wFhASClXv1Qo4eAoJeLhKQFRj7+ov7R1f762eP+3AFxAVMBmgHjLfwBmdq8lKCytAAAAAABAAAAAARNBg0ABgAACQEjASE1IQRN/aLLAkD8+gPvBcn6NwVgrQAAAwAA/+YESgYnABUAHwApAAABJDU0JDMyFhUQBRUEERQEIyIkNRAlATQmIyIGFRQXNgEEFRQWMzI2NTQBtv7rAQTKufD+3wFT/un6zf7+AUwBnIJvaJLz+P78/uGoh4OkAy+B9avXyqD+/osEev7aweXitAEohwF7aHh9YcJlZ/7qdNhwkI9r4QAAAAACAAD/5gRGBicAFwAjAAA3FjMyEhEGJwYjIgA1NAAzMgAREAAhIicTFBYzMjY1NCYjIga5gJTQ5QICZvHD/wABGN/nAQT+sP7Xo3FxoI16pqWHfaTSSgFIAS4CAsIBDNbkASX+lf6l/lP+MjUEHJy3p3en274AAAAAABAAxgABAAAAAAABAA8AAAABAAAAAAACAAcADwABAAAAAAADAA8AFgABAAAAAAAEAA8AJQABAAAAAAAFAAsANAABAAAAAAAGAA8APwABAAAAAAAKACsATgABAAAAAAALABMAeQADAAEECQABAB4AjAADAAEECQACAA4AqgADAAEECQADAB4AuAADAAEECQAEAB4A1gADAAEECQAFABYA9AADAAEECQAGAB4BCgADAAEECQAKAFYBKAADAAEECQALACYBfmZhbmdjaGFuLXNlY3JldFJlZ3VsYXJmYW5nY2hhbi1zZWNyZXRmYW5nY2hhbi1zZWNyZXRWZXJzaW9uIDEuMGZhbmdjaGFuLXNlY3JldEdlbmVyYXRlZCBieSBzdmcydHRmIGZyb20gRm9udGVsbG8gcHJvamVjdC5odHRwOi8vZm9udGVsbG8uY29tAGYAYQBuAGcAYwBoAGEAbgAtAHMAZQBjAHIAZQB0AFIAZQBnAHUAbABhAHIAZgBhAG4AZwBjAGgAYQBuAC0AcwBlAGMAcgBlAHQAZgBhAG4AZwBjAGgAYQBuAC0AcwBlAGMAcgBlAHQAVgBlAHIAcwBpAG8AbgAgADEALgAwAGYAYQBuAGcAYwBoAGEAbgAtAHMAZQBjAHIAZQB0AEcAZQBuAGUAcgBhAHQAZQBkACAAYgB5ACAAcwB2AGcAMgB0AHQAZgAgAGYAcgBvAG0AIABGAG8AbgB0AGUAbABsAG8AIABwAHIAbwBqAGUAYwB0AC4AaAB0AHQAcAA6AC8ALwBmAG8AbgB0AGUAbABsAG8ALgBjAG8AbQAAAAIAAAAAAAAAFAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAACwECAQMBBAEFAQYBBwEIAQkBCgELAQwAAAAAAAAAAAAAAAAAAAAA
这里遇到了一点坑就是,往下写着写着发现每次请求的字体都有可能不一样,这里就卡了很久,坑坑洼洼就不写了。
那么我们就想办法获取每次请求的字体
首先我们要获取字体的内容,并保存到本地:1
2
3
4
5
6
7
8
9
10
11#从html源码中提取出加密后的内容
def get_base64_str(html):
base_font = re.compile("base64,(.*?)\'")
base64_str = re.search(base_font, html).group().split(',')[1].split('\'')[0]
return base64_str
#将加密后的内容保存到本地当中
def make_font_file(base64_str):
b = base64.b64decode(base64_str)
with open("58.ttf","wb") as f:
f.write(b)
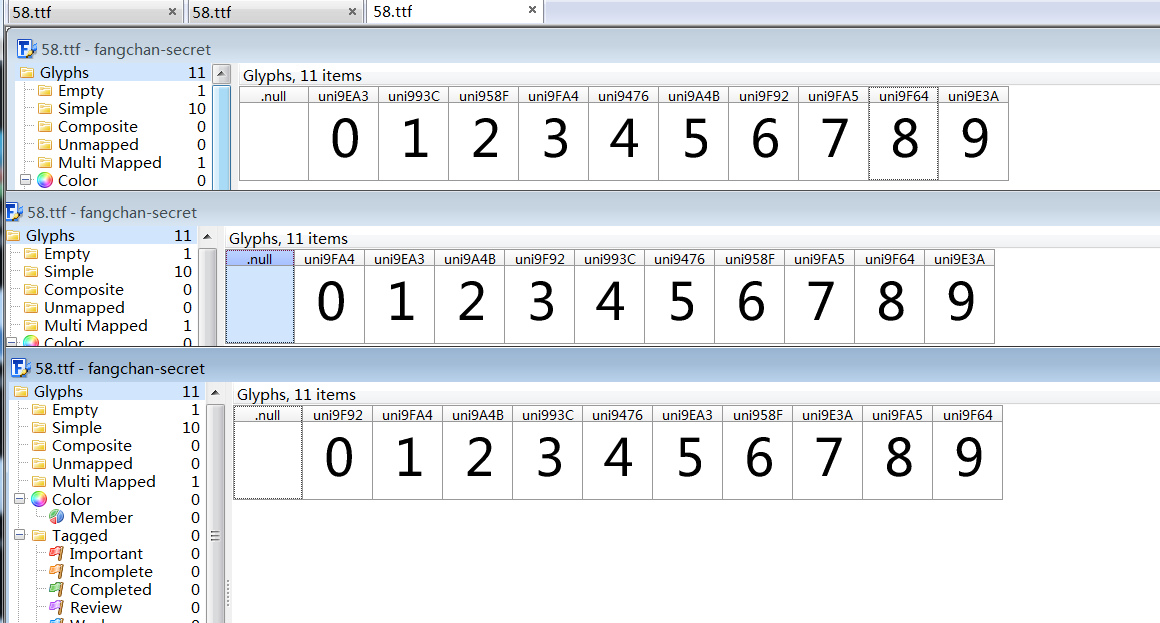
可以发现,每次的字体都不一样
我们就拿出一个字体来进行接下解密的操作。
首先解析成xml格式的文件:1
2
3from fontTools.ttLib import TTFont
font = TTFont('C:\\58.ttf')
font.saveXML('C:\\58.xml')
打开58.xml文件,里面有很多东西,但是我们并不是所有的都要,我们看关键的地方:1
2
3
4
5
6
7
8
9
10
11
12
13
14<GlyphOrder>
<!-- The 'id' attribute is only for humans; it is ignored when parsed. -->
<GlyphID id="0" name="glyph00000"/>
<GlyphID id="1" name="glyph00001"/>
<GlyphID id="2" name="glyph00002"/>
<GlyphID id="3" name="glyph00003"/>
<GlyphID id="4" name="glyph00004"/>
<GlyphID id="5" name="glyph00005"/>
<GlyphID id="6" name="glyph00006"/>
<GlyphID id="7" name="glyph00007"/>
<GlyphID id="8" name="glyph00008"/>
<GlyphID id="9" name="glyph00009"/>
<GlyphID id="10" name="glyph00010"/>
</GlyphOrder>
这里指定了id和name一一对应的关系
接下来往下看:1
2
3
4
5
6
7
8
9
10
11
12<cmap_format_4 platformID="0" platEncID="3" language="0">
<map code="0x9476" name="glyph00005"/><!-- CJK UNIFIED IDEOGRAPH-9476 -->
<map code="0x958f" name="glyph00007"/><!-- CJK UNIFIED IDEOGRAPH-958F -->
<map code="0x993c" name="glyph00004"/><!-- CJK UNIFIED IDEOGRAPH-993C -->
<map code="0x9a4b" name="glyph00003"/><!-- CJK UNIFIED IDEOGRAPH-9A4B -->
<map code="0x9e3a" name="glyph00008"/><!-- CJK UNIFIED IDEOGRAPH-9E3A -->
<map code="0x9ea3" name="glyph00006"/><!-- CJK UNIFIED IDEOGRAPH-9EA3 -->
<map code="0x9f64" name="glyph00010"/><!-- CJK UNIFIED IDEOGRAPH-9F64 -->
<map code="0x9f92" name="glyph00001"/><!-- CJK UNIFIED IDEOGRAPH-9F92 -->
<map code="0x9fa4" name="glyph00002"/><!-- CJK UNIFIED IDEOGRAPH-9FA4 -->
<map code="0x9fa5" name="glyph00009"/><!-- CJK UNIFIED IDEOGRAPH-9FA5 -->
</cmap_format_4>
这里的code就是我们加密后的值。
我们了解这么多就行了,所以我们解码的流程就是,首先找到我们的code值,然后通过code找到对应的name,最后通过name找到对应的id值就行啦。
1 | #获取code和name的dict |
然后我们写好id和name之间的关系:1
2
3
4
5
6
7
8
9
10
11
12
13def num_num():
dict = {}
dict['glyph00000'] = 0
dict['glyph00001'] = 1
dict['glyph00002'] = 2
dict['glyph00003'] = 3
dict['glyph00004'] = 4
dict['glyph00005'] = 5
dict['glyph00006'] = 6
dict['glyph00007'] = 7
dict['glyph00008'] = 8
dict['glyph00009'] = 9
return dict
最后把上面的几个函数结合在一起,就是我们解密的代码了:1
2
3
4
5
6
7
8def get_guanzhu(soup):
dict_1 = get_xml_num()
dict_2 = num_num()
name = soup.select("#pagelet-user-info > div.personal-card > div.info2 > p.follow-info > span.focus.block > span.num")
num = re.findall("ue[^*?]{3}",str(name))
# print(str(name[0]))
for i in num:
print(dict_2.get(dict_1.get(str(i).replace("ue","0xe"))))
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 sher10cksec@foxmail.com
文章标题:58爬虫租房信息
本文作者:sher10ck
发布时间:2019-06-26, 19:44:45
最后更新:2020-01-13, 12:46:46
原始链接:http://sherlocz.github.io/2019/06/26/58-spider/版权声明: "署名-非商用-相同方式共享 4.0" 转载请保留原文链接及作者。