爬取抖音遇见方形文字的问题
闲来无聊,写会爬虫爬爬抖音
QUESTION
这里爬爬Angelababy的主页:1
url:https://www.iesdouyin.com/share/user/80812090202
获取名称:1
2
3
4
5
6
7
8
9
10
11
12
13
14#-*-coding:utf-8-*-
import requests
from bs4 import BeautifulSoup
url = "https://www.iesdouyin.com/share/user/80812090202"
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'
}
r = requests.get(url,headers=headers)
# print(r.content)
soup = BeautifulSoup(r.content,'lxml')
name = soup.select("#pagelet-user-info > div.personal-card > div.info1 > p.nickname")
print(name[0].text)
这里要设定UA,不然返回404
然后想爬取其他的信息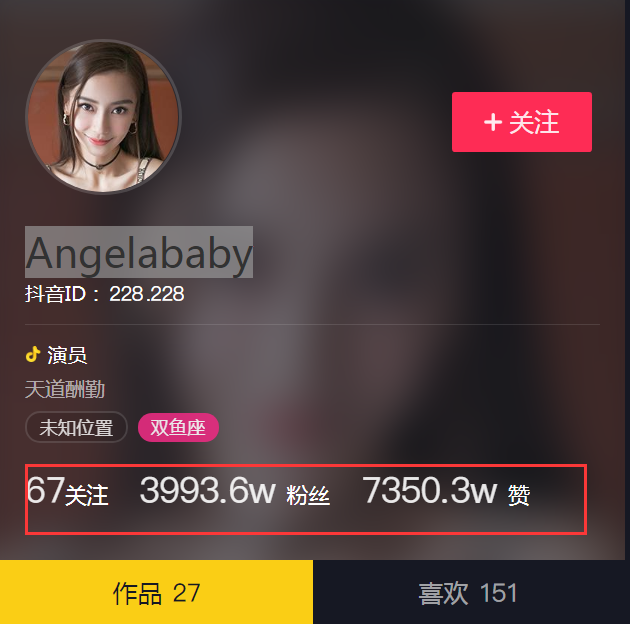
看看网页源代码
看清楚,这里的数字都变成了什么鬼,很明显有了反爬虫机制吧
ANSWER
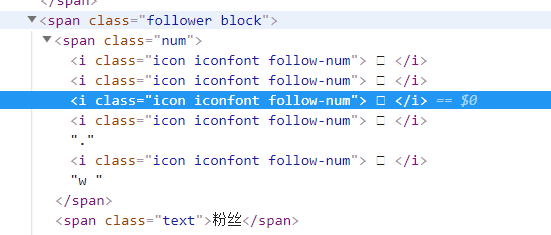
看下我们requests返回的源码,这里面原来的文字都变成了、这种字样。
这里把我们认识的文字解析成了服务器能识别的东西,但是我们自己看不懂,那么我们要想办法转换成我们认识的文字。
1 | pip install fontTools |
用这个第三方库,可以将我们的字体转换成xml格式,我们从抖音的这个页面找到我们的字体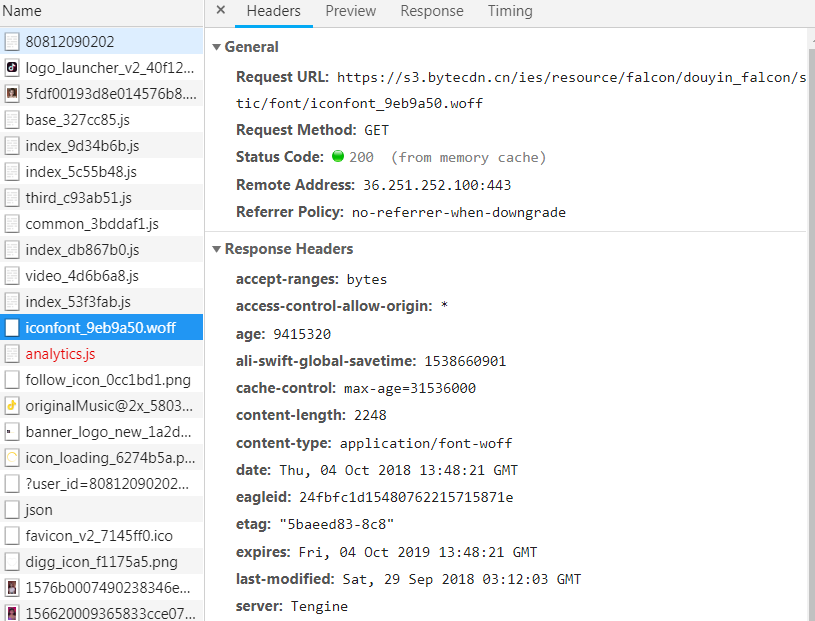
1
https://s3.bytecdn.cn/ies/resource/falcon/douyin_falcon/static/font/iconfont_9eb9a50.woff
点击链接就可以下载这套字体,保存到c:\iconfont_9eb9a50.woff
我们用上面的这个fontTools库转换成xml:1
2
3from fontTools.ttLib import TTFont
font = TTFont('c:\\iconfont_9eb9a50.woff')
font.saveXML('c:\\1.xml')
打开我们的1.xml文件:
1 | <GlyphOrder> |
是不是很熟悉了,上面的id都有一个num值,下面的num都有对应的编码吧,这样的思路问题就解决啦~
通过正则获取上面的id/num/code:1
2
3
4
5
6
7
8
9
10
11def get_xml_num():
dict = {}
with open("c:/1.xml","r") as f:
for line in f.readlines():
content = re.findall('code="([^"]*?)" name="([^"]*?)"',line)
if content:
code = content[0][0]
num = content[0][1]
dict[code] = num
# print("code:" +content[0][0] + "|" + "num:" + content[0][1])
return dict
获取关注量:1
2
3
4
5
6def get_guanzhu(soup):
dict = get_xml_num()
name = soup.select("#pagelet-user-info > div.personal-card > div.info2 > p.follow-info > span.focus.block > span.num")
num = re.findall("ue[^*?]{3}",str(name))
for i in num:
print(dict.get(str(i).replace("ue","0xe")))
这输出为num_6和num_8,但是很明显看见我们上面的关注量应该是67,说明num数并不是和我们的数字相对应的。
这里就真的无解了,只能自己一个一个猜解?后来找到了一个字体打开的软件FontCreator,打开woff之后如下:
是不是发现num和数字对应的区别啦,我们这里再构造一个合集:1
2
3
4
5
6
7
8
9
10
11
12
13def num_num():
dict = {}
dict['num_'] = 1
dict['num_1'] = 0
dict['num_2'] = 3
dict['num_3'] = 2
dict['num_4'] = 4
dict['num_5'] = 5
dict['num_6'] = 6
dict['num_7'] = 9
dict['num_8'] = 7
dict['num_9'] = 8
return dict
这样整个流程就清楚了,首先获取网页的源码,获取源码当中数字的编码,用这些编码找到对应的num_,最后转换成正确的数字。
Python2.7版本源码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51#-*-coding:utf-8-*-
import re
import requests
from bs4 import BeautifulSoup
def num_num():
dict = {}
dict['num_'] = 1
dict['num_1'] = 0
dict['num_2'] = 3
dict['num_3'] = 2
dict['num_4'] = 4
dict['num_5'] = 5
dict['num_6'] = 6
dict['num_7'] = 9
dict['num_8'] = 7
dict['num_9'] = 8
return dict
def get_guanzhu(soup):
dict_1 = get_xml_num()
dict_2 = num_num()
name = soup.select("#pagelet-user-info > div.personal-card > div.info2 > p.follow-info > span.focus.block > span.num")
num = re.findall("ue[^*?]{3}",str(name))
# print(str(name[0]))
for i in num:
print(dict_2.get(dict_1.get(str(i).replace("ue","0xe"))))
def get_xml_num():
dict = {}
with open("c:/1.xml","r") as f:
for line in f.readlines():
content = re.findall('code="([^"]*?)" name="([^"]*?)"',line)
if content:
code = content[0][0]
num = content[0][1]
dict[code] = num
# print("code:" +content[0][0] + "|" + "num:" + content[0][1])
return dict
if __name__ == '__main__':
url = "https://www.iesdouyin.com/share/user/80812090202"
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'
}
r = requests.get(url,headers=headers)
doc = r.content
# print(doc)
soup = BeautifulSoup(doc,'lxml')
# print(soup)
get_guanzhu(soup)
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 sher10cksec@foxmail.com
文章标题:爬取抖音遇见方形文字的问题
本文作者:sher10ck
发布时间:2019-01-21, 21:30:15
最后更新:2020-01-13, 12:46:39
原始链接:http://sherlocz.github.io/2019/01/21/douyin-spider/版权声明: "署名-非商用-相同方式共享 4.0" 转载请保留原文链接及作者。