subdomainbrute源码分析(基础篇)
开了个头
在信息收集的部分,子域名也往往能够给你带来很多惊喜,那么对于子域名信息收集的工具,常用的一款是Layer的子域名挖掘机,另外一款就是要介绍的subdomainbrute了,据说可以发现不少的内网域名、IP(段)、甚至是十分隐蔽的后台。
这么优秀的工具,你不想知道他是怎么实现的吗,知道原理了,自己也可以写写好的工具。
(本文较长,希望大家找个安静的地方,多动手多思考,你也可以搞定这套源码!)
- 项目地址:https://github.com/lijiejie/subDomainsBrute
- 测试环境:Windows Python2.7 运行时要安装相应的模块,根据提示pip install就好啦
- 调试工具:PyCharm Sublime
- 目录结构:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20C:.
│ .gitignore
│ README.md //说明文档
│ screenshot.png
│ subDomainsBrute.py //运行的主Py
│
├─dict //字典文件
│ dns_servers.txt
│ next_sub.txt
│ next_sub_full.txt
│ sample_qq.com.txt
│ subnames.txt
│ subnames_all_5_letters.txt
│ subnames_full.txt
│
└─lib //配置文件
cmdline.py
common.py
consle_width.py
__init__.py
这系列的文章主要是针对比较基础的同学们,希望大家能看懂我写的什么,所以会写的详细一点。
首先我们来介绍导入的模块,并进行实例分析,我这里不会细讲,就讲讲用到的方法和函数,讲太多了也消化不了。你要是想更加详细的去了解相关的信息,可以去查询相关的学习资料,但是我希望我这里写的更容易让大家理解,也记录一下解读过程中的一些坑坑洼洼。(PS:很重要,不然后面看不懂)
dnspython
用Python实现DNS解析1
2
3
4
5
6
7
8
9
10import dns.resolver //导入模块
resolver = dns.resolver.Resolver(configure=False) //创建一个Resolver对象,configure指定不使用你OS上面的DNS,默认为True
resolver.nameservers = ['8.8.8.8'] //指定一个DNS地址
ans = resolver.query("butian.360.cn","A") //查询函数,A代表A记录,也可以查询cname,MX记录等
print(ans[0].address) //ans中的第一个元素,第二个就超过索引值了
result:
112.25.60.167
[Finished in 0.5s]
那我们来看看源码中lib\common.py中的test_server()函数1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29def test_server(server, dns_servers):
resolver = dns.resolver.Resolver(configure=False)
resolver.lifetime = resolver.timeout = 6.0
try:
resolver.nameservers = [server]
answers = resolver.query('public-dns-a.baidu.com') # test lookup an existed domain
if answers[0].address != '180.76.76.76':
raise Exception('Incorrect DNS response')
try:
resolver.query('test.bad.dns.lijiejie.com') # Non-existed domain test
with open('bad_dns_servers.txt', 'a') as f:
f.write(server + '\n')
print_msg('[+] Bad DNS Server found %s' % server)
except:
dns_servers.append(server)
print_msg('[+] Server %s < OK > Found %s' % (server.ljust(16), len(dns_servers)))
except:
print_msg('[+] Server %s <Fail> Found %s' % (server.ljust(16), len(dns_servers)))
别慌,认真看看其实并不难:
1、(line1)函数输入了server和dns_servers,都是列表,其中dns_servers为空列表,server是有元素的列表,这里应该只有一个,具体怎么来的我们后面再说
2、(line2)初始化了一个Resolver对象
3、(line3)定义了这个对象的生命周期和超时(看不懂别管他)
4、(line5)指定了DNS
5、(line6-8)首先指定了一个存在的网址,要是解析出来的ip是正确的话,那么就将这个server添加到dns_server中
6、(line9-15)指定一个不存在的网址,要是解析的出来就是真的有鬼了,所以try中的执行错误,就直接执行except了
7、print_msg()是作者自己写的函数,源码也在这个脚本中自己看下,大佬还是大佬啊
我们接着看下一个
optparse
这是一个命令行相关的模块,也就是我们添加什么参数,就是用这个来实现的,直接贴源码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16import optparse
parse=optparse.OptionParser(usage='"usage:%prog [options] arg1,arg2"',version="%prog 1.2")
parse.add_option('-u','--user',dest='user',action='store',type=str,metavar='user',help='Enter User Name!!')
parse.add_option('-p','--port',dest='port',type=int,metavar='xxxxx',default=3306,help='Enter Mysql Port!!')
options,args= parse.parse_args()
1、usage 定义的是使用方法,%prog 表示脚本本身,version定义的是脚本名字和版本号
2、dest='user' 将该用户输入的参数保存到变量user中,可以通过options.user方式来获取该值
3、type=str,表示这个参数值的类型必须是str字符型,如果是其他类型那么将强制转换为str(可能会报错)
4、metavar='user',当用户查看帮助信息,如果metavar没有设值,那么显示的帮助信息的参数后面默认带上dest所定义的变量名
5、help='Enter..',显示的帮助提示信息
6、default=3306,表示如果参数后面没有跟值,那么将默认为变量default的值
7、最后一句定义了两个返回值,可以通过options.user获取输入的user值
源码在lib\cmdlines.py中,这里就不贴上了,附上一张这个案例运行的效果: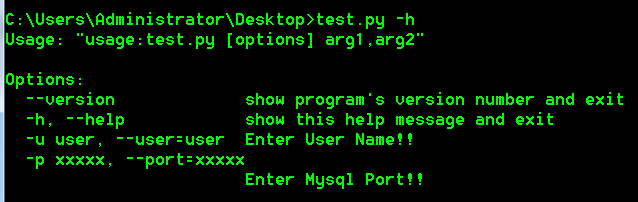
multiprocessing*
这里我们讲讲多线程和多进程的区别:一个餐馆有
一张桌子一个凳子(单进程单线程)
一张桌子多个凳子(单进程多线程)
多张桌子一个凳子(多进程单线程)
多张桌子多个凳子(多进程多线程)
那么multiprocessing就是我们要学习的多进程啦,多线程threading可以自行搜索,这里就不讲了。对于multiprocessing,我们通常用到的有两种模块来定义进程:1
2from multiprocessing import Processing
from multiprocessing import Pool
Pool类用于需要执行的目标很多,而手动限制进程数量又太繁琐时,如果目标少且不用控制进程数量则可以用Process类。其中Pool可以控制进程数。(PS:你可以打开任务管理器来监视进程、线程数)
Example1: 用Process创建进程1
2
3
4
5
6
7
8
9
10
11
12
13
14from multiprocessing import Process
import os
# 子进程要执行的代码
def run_proc(name):
print 'Run child process %s (%s)...' % (name, os.getpid())
if __name__=='__main__':
print 'Parent process %s.' % os.getpid()
p = Process(target=run_proc, args=('test',))
print 'Process will start.'
p.start() //启动进程
p.join() //执行完当前进程之后再向下进行。你可以尝试注释这句代码,可观察到不一样的效果
print 'Process end.'
Example2: 用Pool创建进程1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19from multiprocessing import Pool
import os, time, random
def long_time_task(name):
print 'Run task %s (%s)...' % (name, os.getpid())
start = time.time()
time.sleep(random.random() * 3)
end = time.time()
print 'Task %s runs %0.2f seconds.' % (name, (end - start))
if __name__=='__main__':
print 'Parent process %s.' % os.getpid()
p = Pool() //这里可以设置进程数,你输入0-10会发现不同的效果
for i in range(10):
p.apply_async(long_time_task, args=(i,))
print 'Waiting for all subprocesses done...'
p.close() //join之前必须close,不然会报错,这里是close之后就无法添加其他的进程了
p.join() //执行完当前进程之后再向下进行。你可以尝试注释这句代码,可观察到不一样的效果
print 'All subprocesses done.'
来看源码里的例子:
subdomainbrute.py (line242-250)1
2
3
4
5
6
7
8
9
10
11
12for process_num in range(options.process):
p = multiprocessing.Process(target=run_process,
args=(args[0], options, process_num,
dns_servers, next_subs,
scan_count, found_count,queue_size_list,
tmp_dir)
)
all_process.append(p)
p.start()
1、options.process是你输入命令行设置的进程数,默认为6
2、调用了run_process()函数,这个函数后面具体再讲
lib\common.py1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20def load_dns_servers():
print_msg('[+] Validate DNS servers', line_feed=True)
dns_servers = []
pool = Pool(10)
for server in open('dict/dns_servers.txt').readlines():
server = server.strip()
if server:
pool.apply_async(test_server, (server, dns_servers))
pool.join()
dns_count = len(dns_servers)
print_msg('\n[+] %s available DNS Servers found in total' % dns_count, line_feed=True)
if dns_count == 0:
print_msg('[ERROR] No DNS Servers available!', line_feed=True)
sys.exit(-1)
return dns_servers
1、(line4)定义了进程数为10
2、(line8)调用了test_server函数,结合上面讲DNS一起看,知道server和dns_servers是怎么来的了吧
3、注意这里pool并没有close,额,不知道作者忘记了还是啥
gevent
这里又要搞清楚一个概念,就是协程,那协程是什么呢?
在linux系统中,线程就是轻量级的进程,而我们通常也把协程称为轻量级的线程即微线程。
线程是在进程中做切换,那么协程就可以相当于在线程当中做切换。
1 | from gevent import monkey; monkey.patch_socket() |
总了个结
要是你把上面的几个模块弄懂了,那么恭喜你,对于subdomainbrute这个脚本,你已经基本上搞定了。
要是懵懵懂懂的,也别着急,一口气吞不下慢慢来,多动手,多动脑。
脚本中其他的模块,还有像os、time、signal这些比较常用的就不在这里一一介绍啦,要是不了解的话,多洞洞手指哦。
希望大家能够好好掌握这些知识,平时开发写自己脚本的过程中用的地方都是很多的。
下一篇介绍subdomainbrute脚本的整个流程,再见啦。
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 sher10cksec@foxmail.com
文章标题:subdomainbrute源码分析(基础篇)
本文作者:sher10ck
发布时间:2019-01-11, 12:21:56
最后更新:2020-01-13, 13:01:17
原始链接:http://sherlocz.github.io/2019/01/11/subdomainbrute/版权声明: "署名-非商用-相同方式共享 4.0" 转载请保留原文链接及作者。