对一款轻量级Github泄露工具的源码分析
最近看见一款Github泄露工具,好像挺好用的就拿过来看看,主要检查目标是否在Github上泄露了什么信息,毕竟是信息收集工具哈。
- 项目地址:https://github.com/dongfangyuxiao/github_dis/
测试环境:Ubuntu16.04 Python2.7
在windows下可能会报错,要导入:1
2from requests.packages.urllib3.exceptions import InsecureRequestWarning
requests.packages.urllib3.disable_warnings(InsecureRequestWarning)目录结构:
1
2
3
4
5
6
7
8config.py //估计是之前的测试脚本,没什么用
github.py //运行的主要脚本
github.txt //爬取的结果
keyword.txt //搜索的关键字
README.md //文档说明
requestsment.txt //Python需要的库文件
type.txt //搜索的配置信息
__init__.py //初始化函数
0x00 初探
首先运行下看看效果,打印出来的格式为:
https://github.com/search?q=keywords1+keywords2&type=code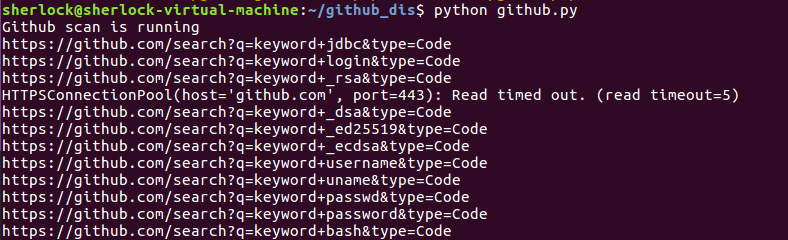
再看github.txt中的内容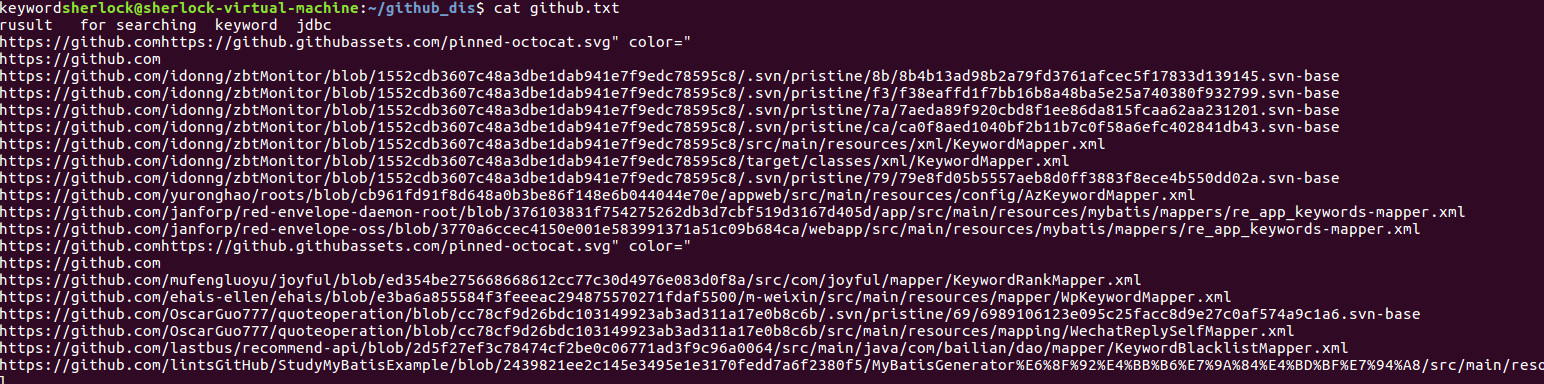
这个内容就是我们爬取的搜索关键词得到的链接呀。
然后大致看了下源码,整个流程是这样的:
- 从文件中获取关键词(keywords)
- 登录github(不登录无法搜索)
- 从github中搜索keywords
- 爬取搜索结果的链接
0x01 github.py
1 | if __name__ == "__main__": |
创造了一个Github对象,并调用了run()方法
看这个对象的初始化函数:1
2
3
4
5
6
7
8
9
10
11
12
13def __init__(self):
print "Github scan is running"
self.headers = {
'Referer': 'https://github.com/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:64.0) Gecko/20100101 Firefox/64.0 ',
'Cache-Control': 'no-cache',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
}
self.cookies = ""
self.load_keyword()
self.load_type()
self.__auto_login()
定义了headers和cookies值,并调用了三个函数:
load_keyword()
1
2
3
4
5
6
7def load_keyword(self):#加载关键字,存入队列
self.key = Queue.Queue()
with open('keyword.txt') as f:
for line in f:
self.key.put
从文件keyword.txt中读取keywords1load_type()
1
2
3
4
5
6
7def load_type(self):#加载搜索类型,存入队列
self.type = Queue.Queue()
with open('tee.txt') as f:
for line in f:
self.type.put(line.strip())
从文件type.txt中读取keywords2__auto_login()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34def __auto_login(self):# github登录
"""
Get cookie for logining GitHub
:returns: None
"""
login_request = requests.Session()
login_html = login_request.get("https://github.com/login", headers=self.headers,verify=False)
post_data = {}
soup = BeautifulSoup(login_html.text, "lxml")
input_items = soup.find_all('input')
for item in input_items:
post_data[item.get('name')] = item.get('value')
post_data['login'], post_data['password'] = "xiaodongtest", "xiaodongtest123"#这里可以换成你自己的github账号,建议申请个小号,不然会被封
login_request.post("https://github.com/session", data=post_data, headers=self.headers,verify=False)
self.cookies = login_request.cookies
#print self.cookies
if self.cookies['logged_in'] == 'no':
print('[!_!] ERROR INFO: Login Github failed, please check account in config file.')
exit()
登录到github
__auto_login()函数注意下:
1、它刚开始请求的页面是**https://github.com/login**,但是这个页面上的请求其实是以POST方式提交给了**https://github.com/session**,这个是github登录时候的一个小跳转
2、post_data为提交给**https://github.com/session**的数据,本来post_data的值为:
{'commit': 'xxx', 'utf8': 'xxx', 'login': None, 'password': None, 'authenticity_token': 'xxx'}
发现这里的login和password值都为None,那么语句
post_data['login'], post_data['password'] = "xiaodongtest", "xiaodongtest123"
为赋值语句
{'commit': 'xxx', 'utf8': 'xxx', 'login': 'xiaodongtest', 'password': 'xiaodongtest123', 'authenticity_token': 'xxx'}
最终将这个post_data以post方式发送出去
login_request.post("https://github.com/session", data=post_data, headers=self.headers,verify=False)
3、cookies的值要是返回中**Cookie logged_in=yes for .github.com**则为登陆成功,反之**Cookie logged_in=no for .github.com**会报错
看下剩余函数:
write()
1
2
3def write(self,line):#把查找到的信息写入文件
with open('github.txt','a+') as f:
f.write(line+'\n')search()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19def seach(self,url):#爬虫爬取页面
new_list=[]
code_pattern = re.compile('href="(.*?)#')
try:
resc = requests.get(url, headers=self.headers, cookies=self.cookies,timeout=5, verify=False)
code_list = code_pattern.findall(resc.content)
for x in code_list:
if x not in new_list:
new_list.append(x)
x = 'https://github.com'+x
#print x
self.write(x)
# print x
# time.sleep(random.uniform(1, 3))
except Exception as e:
print e
pass
将爬取的目标连接添加在new_list中,再write()写入到文件里面run()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31def run(self):
while not self.key.empty():
keyword = self.key.get()
#print keyword
while not self.type.empty():
type= self.type.get()
pattern = re.compile('data-search-type="Code">(.*?)</span>')
url = "https://github.com/search?q={0}+{1}&type=Code".format(keyword, type)
print url
self.write('rusult for searching '+keyword +' '+ type)
try:
res = requests.get(url, headers=self.headers, cookies=self.cookies,timeout=3, verify=False)
# print res.content
pages = pattern.findall(res.content)
#print pages
if 'K' or 'M' in pages[0]:
pages[0]=int(100)#超过1000页,只搜搜前100页
pmax = int(math.ceil(int(pages[0]) / 10) + 2)#先去判断总共有多少页
#print pmax
time.sleep(random.uniform(1, 2))#随机sleep random
for p in range(1, pmax):
courl = "https://github.com/search?p={0}&q={1}+{2}&type=Code".format(p, keyword, type)
self.seach(courl)
except Exception as e:
print e
pass
1、self.key.get() 是从load_keyword中获取的队列
2、self.type.get() 是从load_type中获取的队列
3、这段代码主要是为了控制获取的数量,那怎么控制的呢?首先在搜索后的页面上获取Code的总数,比方说Code超过1000就会显示1K,超过一百万会显示1M,那么正则表达式pattern就是为了获取这个数量,要是获取的字符中含有"K"或者"M",那么我们还是获取前100页,用一个sleep()函数保持速度防止速递过快被ban掉,最后每个页面调用search()函数。
0x03 总了个结
对于脚本来说,最重要的就是思路了,不同的思路对于脚本的效果有很大的关系。
那么对于这个脚本,整体的思路就是登陆github之后爬取想要的东西,思路很简单,其他的用代码去实现啦。
对于Github源码泄露,可能会发现网站的敏感信息(包括网站源码、配置信息、管理员账号密码等等),这个脚本速度不是很好,期待看见更好的脚本。
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 sher10cksec@foxmail.com
文章标题:对一款轻量级Github泄露工具的源码分析
本文作者:sher10ck
发布时间:2019-01-09, 13:02:47
最后更新:2020-01-13, 13:00:08
原始链接:http://sherlocz.github.io/2019/01/09/github-dis/版权声明: "署名-非商用-相同方式共享 4.0" 转载请保留原文链接及作者。